
Paper Journal: Disaggregated Serving
Achieving consistent online LLM inference performance

In this article, I won’t build anything From Scratch. Instead, I’ll cover a recent research paper DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving whose findings have since been implemented in vLLM.
DistServe tackles one of the most critical challenges in LLM deployment today: how to maintain consistent performance under high request loads. By disaggregating the prefill and decode stages of LLM inference, DistServe can satisfy the same Service Level Objectives (SLOs) at up to 7x higher request rates compared to traditional approaches.
This innovation is particularly important for LLM API providers like Google or OpenAI, where predictable performance is essential for user experience.
In this post, I’ll provide a short overview of generative LLM inference and go over DistServe’s internals.
Generating text with LLMs
Let me briefly illustrate how the generative process works. This will be important to appreciate the core insight behind DistServe.

Decoder-only models are next-token predictors, in other words, every forward pass assigns a likelihood to each token in the model’s vocabulary. Then depending on the sampling function used, one of the most-likely tokens is selected. In the example above I’m using simple greedy sampling.
I’ll be using the terms token and word interchangeably.
A naive way to implement the generative loop would be to take the token generated at step 0, append it to the user input, rerun the whole modified input through the model, and repeat until termination. As you can imagine, this would be prohibitively expensive.
Decoder-only transformers commonly use causal attention — a context mechanism where the hidden representations of input tokens are functions of the hidden representations of preceding tokens and of the current token.
This allows inference engines to cache all of the intermediate tensors that will be required in subsequent generation passes. For instance, on the first iteration of the example above, all intermediate tensors that are required for the attention layer will be cached. On the second iteration, it’s sufficient to compute the forward pass just for the token “Apples” and substitute in the cached tensors where required.
This technique is known as KV (Key-Value) caching since the intermediate tensors that need to be cached are the K, V attention tensors.
Two phases of LLM inference
You might notice that not all steps in the generative loop above are created equal. The first step, often called the prefill or context phase, is much more computationally intensive.
Similar to how website load times are measured, LLM API providers monitor the time to first token (TTFT).
It’s customary to express SLOs in percentiles. For instance, 50ms p99 TTFT would mean that the service has to generate the first token within 50ms for 99% of requests.
In contrast, the subsequent decoding phase benefits from KV caching and is more often memory-bound. A common SLO here is the inter-token latency (ITL).
Taken together, the TTFT + ITL * num_generated_tokens gives the overall request latency.
vLLM setup
Let’s walk through a reasonable inference setup with vLLM. vLLM and DistServe serve a similar purpose, so understanding vLLM will help us appreciate DistServe’s differences.
vLLM is a popular LLM inference library initially developed at UC Berkeley that was the first to introduce paged attention for improving GPU memory utilization. Since then, vLLM has incorporated many common LLM inference optimizations, for instance, quantization, prefix caching, or speculative decoding.
Let’s suppose we have a single machine with two GPUs and each GPU is large enough to fit the entire model we want to serve, say a llama-3-8B.
A pretty reasonable inference setup might look something like this:
Run a separate vLLM llama-3-8B instance on each GPU.
Set up a load balancer in front of these two model instances to distribute incoming requests.
The key limitation here is that both prefill and decode phases run on the same GPU.
vLLM implements continuous batching, where new requests can join the active batch on each generation step, significantly improving throughput. However, this creates a non-obvious issue: requests in the computationally intensive prefill stage can significantly slow down decode operations happening in the same batch.
This makes it difficult to optimize the system for both TTFT and ITL at the same time. While other mitigations have been proposed, for instance, chunked prefill, they have known limitations.
DistServe
The folks behind DistServe noticed this prefill-decode interference and came up with a clever idea to split the two phases. Disaggregating the two phases allowed them to guarantee more predictable TTFT and ITL, allowing them to maintain the same SLOs at several times higher request rates than vLLM.
Splitting these isn’t trivial — the prefill phase generates KV cache blocks required for the decode phase so they had to come up with a mechanism for moving cache blocks between instances.
DistServe is implemented on top of Ray, a popular orchestration platform for Python workloads. DistServe uses Ray actors and placement groups to assign prefill and decode worker instances to GPUs in a Ray cluster.
Let’s explore how exactly DistServe works.
Life of a request
DistServe is implemented as a single API server Python process that spawns and orchestrates Ray workers.
Requests sent to DistServe’s /generate endpoint are added to a prefill queue. The prefill-stage controller has an event loop that on each iteration tries to:
Create a new batch from requests in the prefill queue.
If a batch can be created, it reserves the memory blocks.
Dispatch the batch request to all prefill workers.
Wait for the single prefill forward pass to finish.
Move finished requests to a bridge queue for the decode stage to handle them.
Let me elaborate on the memory blocks. DistServe, like vLLM, implements paged attention — memory for KV cache is partitioned into blocks akin to operating system memory pages. DistServe’s block manager keeps track of all memory blocks. Information about block usage is then used by the scheduler when constructing a new batch.

The new batch is then dispatched to all prefill workers by using Ray’s remote() call. DistServe supports tensor and pipeline parallelism for each stage separately. In this walkthrough, I’ll be assuming no tensor or pipeline parallelism so there’s exactly one worker for each phase.
Being able to configure tensor and pipeline parallelism settings for each stage independently is yet another benefit of splitting prefill and decode stages.
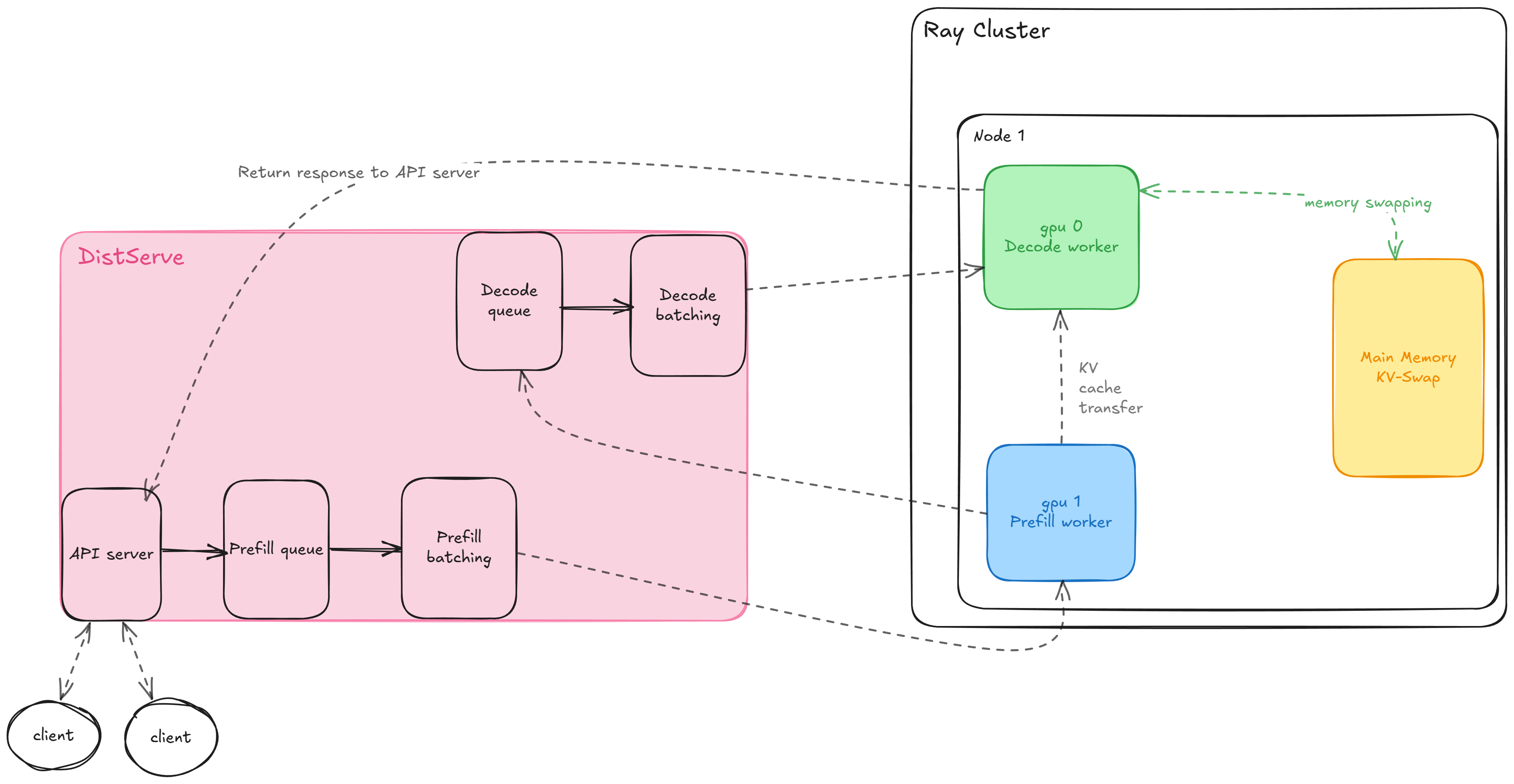
When the prefill forward step finishes, requests are moved to DistServe’s bridge queue. DistServe has a pretty complex queue setup on the decoder side, so I’ve simplified this significantly in the diagram above.
In a nutshell, a request that has finished the prefill phase will stay waiting in a variety of queues until two conditions are met:
Its KV cache blocks can be moved from the prefill worker to the decode worker.
Once KV cache blocks are moved to the decode worker, the scheduler can try to add the request to the next continuously batched batch.
The KV cache migration from a prefill worker to a decode worker is interesting. Once DistServe determines that the decode worker has enough free GPU memory, it will send a request to the decode worker to pull relevant tensors from the prefill worker. DistServe uses a custom execution engine SwiftTransformer in which they implement support for block migration via cudaMemcpyAsync.
Interestingly, DistServe authors found that the transfer overhead even for a relatively large 175B model was only around 0.1% of the total latency. This is largely thanks to high-bandwidth InfiniBand and NVLink GPU-GPU communication links.
DistServe has to ensure that the transfer finishes before the corresponding request can be handled by the decode worker. Once the transfer finishes, the prefill worker can free those memory blocks.
The decode scheduler uses continuous batching. Since each decoding request might require a variable number of iterations to terminate, on each iteration it tries to add a new request whose KV cache blocks were already transferred to the GPU. If memory requirements of existing requests grow more than expected, most recently added requests can be temporarily swapped to main memory.
On each iteration, predicted tokens can be streamed back to users. Once a request is finished, all associated memory blocks can be freed or cached in cheaper storage. Caching can be useful to avoid recomputing everything for chat-like use-cases.
Summary
DistServe is an interesting paper that has gathered well-deserved interest from hyperscalers like Google and OpenAI. By splitting the prefill and decode phases across separate workers, it resolves a fundamental issue with traditional serving systems.
For LLM API providers, the lessons from DistServe can likely lead to a reduced need to overprovision hardware to deal with prefill × decode interference. Disaggregating prefill and decode has since been implemented in vLLM, further showing the relevancy of this finding.
I typically build interesting software From Scratch in my articles. With my background in LLM inference and Kubernetes, DistServe lies in a particularly fun problem space for me, so I made an exception and covered the paper. If there’s interest, I might do these more often :)
If you enjoy deep dives like this, consider subscribing! I’m also somewhat active on LinkedIn, so consider connecting with me there. If you enjoyed this article, you also might enjoy some of the pinned articles below!
Build Your Own Inference Engine: From Scratch to "7"

I like to keep things practical. Let’s train a simple neural network, save the model, and write an inference engine that can execute inputs against the model. Sounds like a fun time to me!
Optimizing matrix multiplication

This article is all about performance optimizations - squeezing as much performance out of my CPU as I can.
Linux container from scratch

I recently built a docker clone from scratch in Go. This made me wonder - how hard would it be to do the same step-by-step in a terminal? Let’s find out!
Great post! I didn’t know about DistServe I have to check it out