
Inference Engine: Optimizing Performance
How I made my inference engine 15x faster

Today I wanted to add graph optimizations to my inference engine, hoping for maybe a 5-10% performance improvement. Instead, I accidentally found a critical bottleneck!
If you haven’t already, you can read about how I wrote an inference engine from scratch here.

Baseline benchmarking
Improving performance is an empirical endeavor. I’ll be using a simple benchmark where the engine executes 500 sequential inference requests.
I’ll be compiling the binary in debug mode throughout this post so that the profiler has access to all debug symbols. In general, benchmarking should probably be done in release mode, but the extra readability will serve us well here.
We can time the execution with time.
time /home/michal/code/inference_engine/build/src/engine_exe /home/michal/code/inference_engine/models/mnist_ffn_complex.onnx
real 0m15.194s
user 0m14.500s
sys 0m0.694sProfiling
I’ll be using perf - a powerful profiler baked into the Linux kernel. To visualize perf’s report, I’ll use an OSS perf GUI Hotspot. This will give us access to nice flame charts.
I’m looking for major bottlenecks so a sampling analysis will work just fine for me.
perf record -o /home/michal/perf.data --call-graph dwarf --aio --sample-cpu /home/michal/code/inference_engine/build/src/engine_exe /home/michal/code/inference_engine/models/mnist_ffn_complex.onnx
The flame chart shows us where code spends the most CPU cycles. The core function in my engine is this InferenceEngine::infer call that I’ve zoomed on. It iterates over the computational graph, loads inputs, and evaluates every node.
Looking closer at the flame chart shows something concerning. Less than 40% of cycles are spent evaluating nodes. InferenceEngine::prepareNodeInputs is taking up a significant amount of time. There are many Tensor memory allocation calls and copy calls.
When I zoom in on the InferenceEngine::evaluateNode call, the story gets worse.
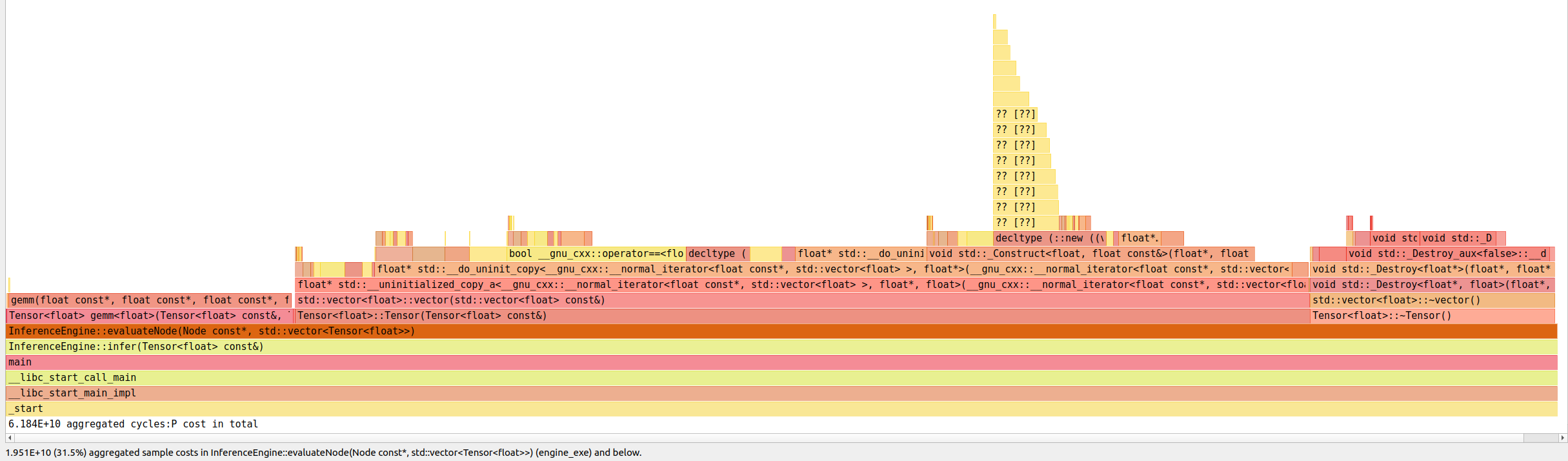
It only spends around 20% of its execution time doing useful work. The rest is spent on copying and destroying Tensors.
Let’s see if we can optimize this.
Optimizing
Let’s look at the InferenceEngine::prepareNodeInputs method.
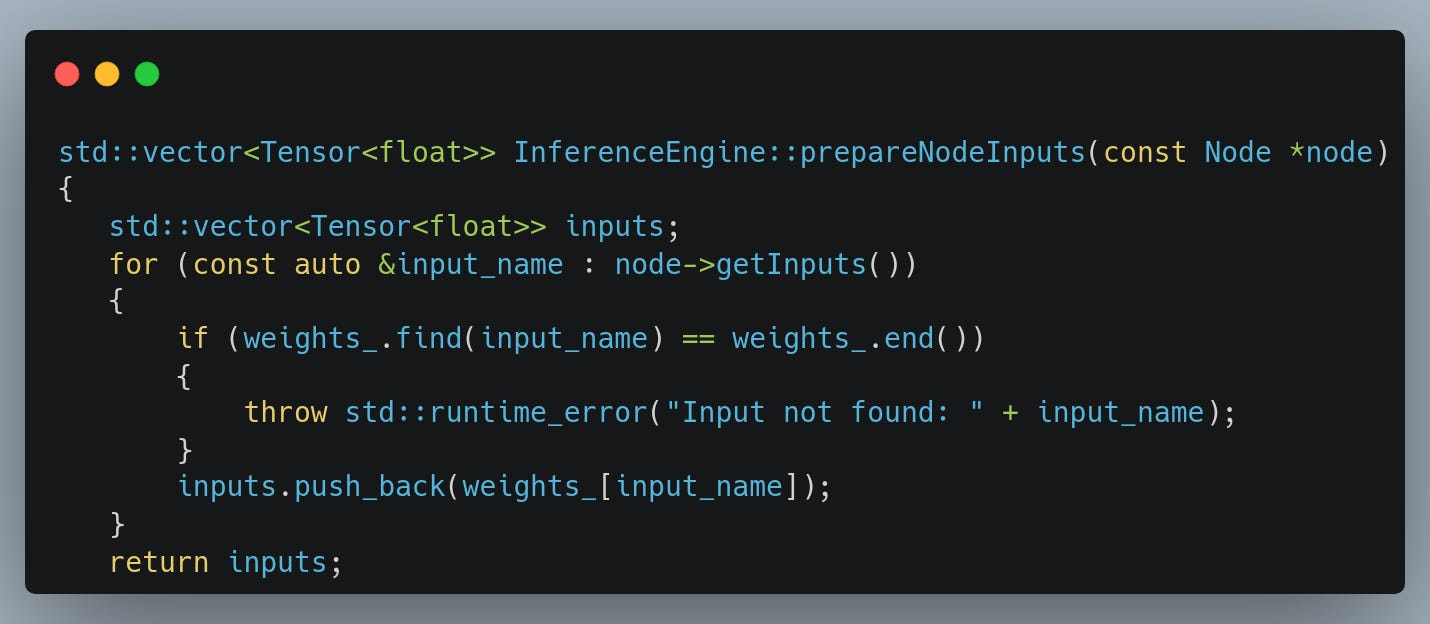
Here we take elements from a map and push them into a vector. Looks innocent enough but it creates a copy of each Tensor. Let’s rework this to instead return a vector of naked pointers to Tensors. While doing so, we can also slightly optimize the map access and pre-allocate a vector of appropriate size.
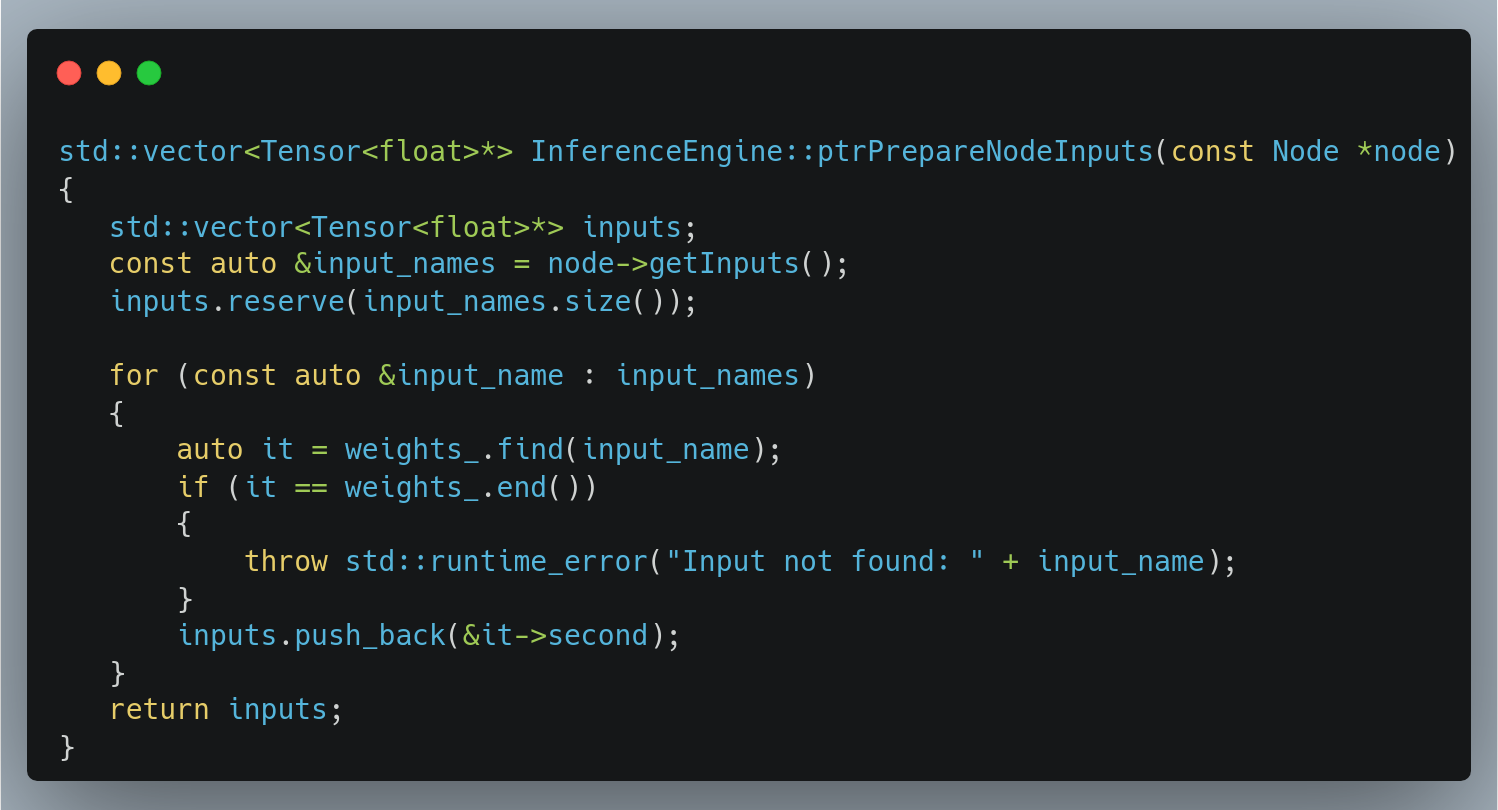
In the flame chart, we saw a bunch of Tensor copies, so I’ve also gone ahead and used pointers or references where applicable in the rest of the InferenceEngine::infer method to minimize the number of unnecessary copies.
Results
To see if our previous changes made a material difference we need to benchmark again:
real 0m1.053s
user 0m1.040s
sys 0m0.013sWow, 15x faster just like that.
Let’s also re-run the profiler to see what proportion of time is spent on useful operations now.
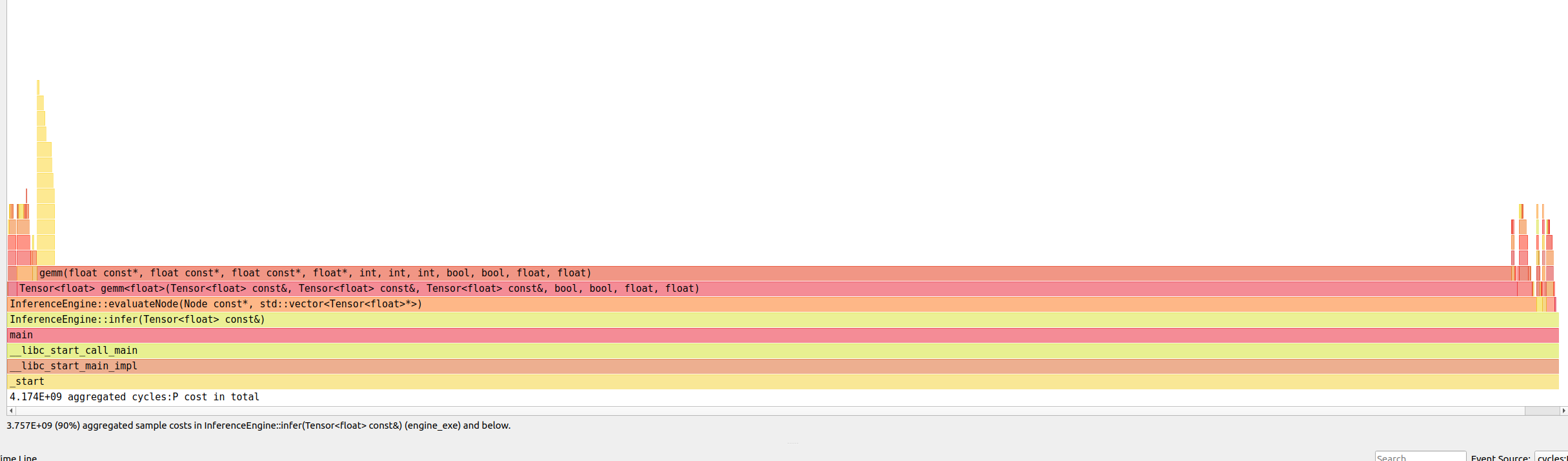
As we can see, now InferenceEngine::evaluateNode constitutes the vast majority of the infer call. Most time is spent on the most complex operation my engine currently supports - generalized matrix multiplication. That’s great!
To overcome the performance limitations imposed by my current GEMM implementation, I plan to explore either offloading the computation to a GPU using CUDA or distributing the workload across multiple CPU cores.
With this in mind, I think I’ll hold off on graph optimizations as they likely won’t provide a significant improvement compared to other optimizations.
I hope you enjoyed this lighter post on performance programming! If you did, consider subscribing and/or following me on LinkedIn!
You might also enjoy some of my other posts. Maybe check out one of the ones linked below?


