
GPU Programming
Writing code for massively parallel processors

One of the great joys of software engineering is dispelling magic. I’ve written code that executed on a GPU using frameworks like PyTorch or TensorFlow, but I never understood the “how”. It’s time to dispel the magic of GPU programming and learn how it works under the hood.
C CUDA basics
C CUDA is Nvidia’s extension of ANSI C. For the most part, it is the same as C with some added syntax and built-in functions. C CUDA gives us control over what parts of our code are executed on the CPU and the GPU. We call code executed on the CPU host code and GPU code device code. Procedures that run on the GPU are for historical reasons called kernels.
Instead of focusing on CUDA itself, let’s write a simple program that blurs an image. I’ll try to fill in the details as needed.
Blurring images
We want to write code to blur an image on a GPU.

Here’s roughly what our code needs to do:
Load the image in the host code
Allocate memory on the GPU
Copy over the input image to the GPU
Blur the image with a kernel
Copy over the output image to the CPU
Save the output image to the disk
First, we need to know how an image is represented in memory and how to blur it. An RGB image is usually thought of as a 3-dimensional matrix of shape (channels, height, width). In memory, it’s usually represented as a flat array in row-major order. Our GPU code will assume this format.

To access the (n, row, col) pixel in a 3-channel image, we can use the following expression.
i = (row*WIDTH + column)*3 + nTo blur an image, we calculate the value of each pixel as the average of surrounding pixels and write the result into the output image.

Can we parallelize this? Of course! Each output pixel only depends on the input image, but has no dependencies on other outputs. If we had a processor with width*height cores, we could process every output pixel in parallel. Turns out, that’s pretty much what GPUs are!
Writing a kernel
Let’s finally write our kernel. It will closely follow the 2D example above, but generalize it to n-channel images.
A kernel in execution is called a thread. Each thread will compute the RGB channels for a single pixel in the image.
To tell each thread which pixel to compute, CUDA automatically injects variables blockIdx, blockDim, and threadIdx into the kernel. We use these to determine which pixel a given thread should process.
Once we know which pixel we are processing, we iterate over the neighboring pixels and accumulate their red, green, and blue values in pixVarR, pixVarG, and pixVarB. We also count the number of pixels we’ve iterated over, to handle cases where the blur-radius reaches beyond the edges of the image.

Note that the coordinate calculation might feel unnatural since the image is flattened as discussed earlier.
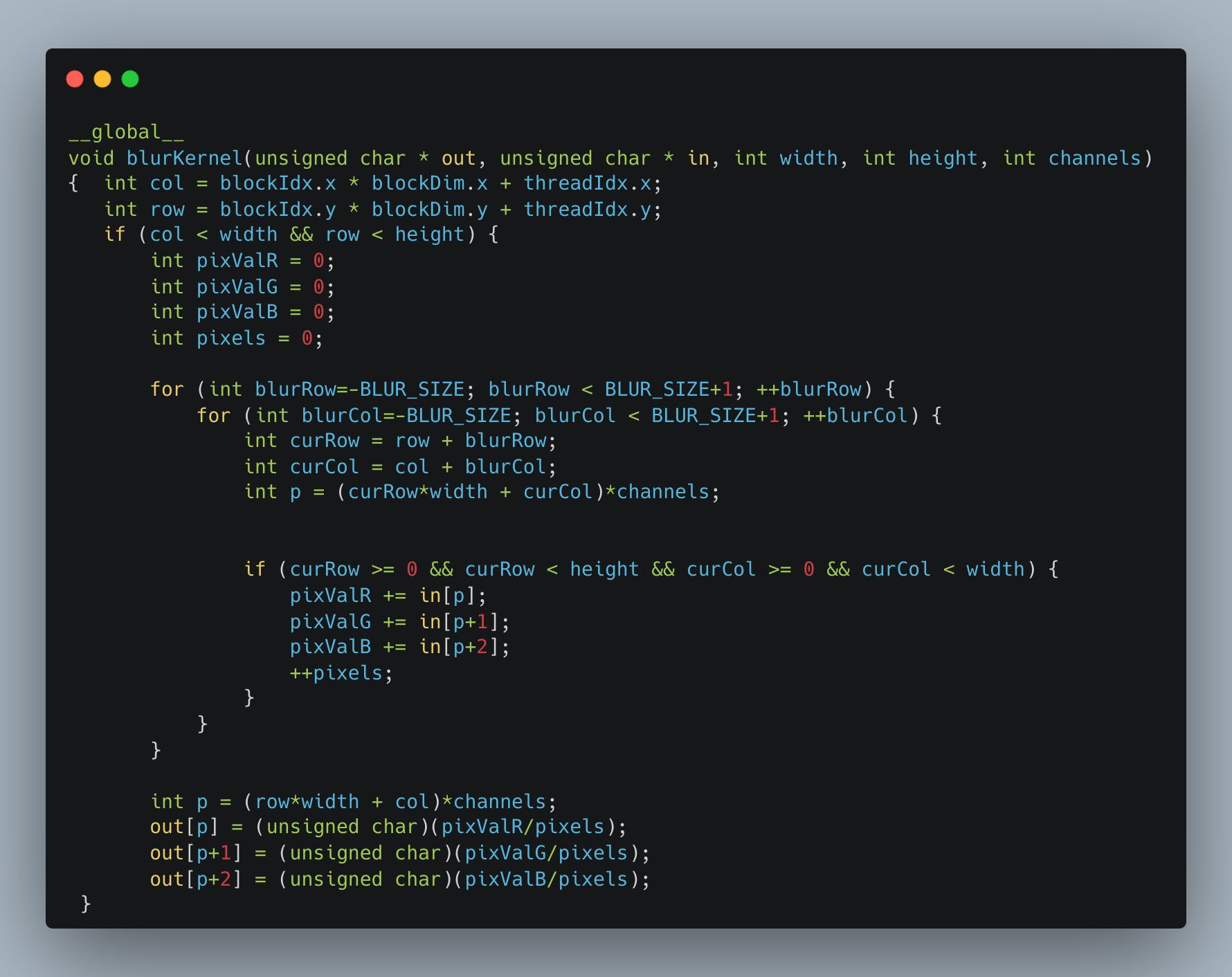
You might notice the special __global__ identifier before the kernel name. This is how we specify that a procedure is a kernel and should be compiled to run on the GPU. It’s also how the c cuda compiler (NVCC) knows to inject the blockIdx, blockDim, and threadIdx variables.
Now that we have the kernel, let’s briefly write the main function to set things up and run it. The main function closely follows the setup steps outlined earlier. The cuda-prefixed functions are automatically included by the NVCC compiler. These mostly copy built-in C functions to provide similar functionality but for GPUs.

The interesting part is when we call the kernel.

We designed our kernel to process all channels for a given pixel with a single thread.
To make it concrete, our lenna.png is of shape 512 * 512, so we need that many threads to process the whole image. My GPU, however, only has 1920 CUDA cores. That’s fine - GPUs are much faster at context switching than CPUs, so having more threads than physical cores is desirable to maximize throughput.
To do this, we use the <<<dimGrid, dimBlock>>> syntax. Each argument is a struct with 3 fields {x, y, z}. The configuration generally follows the shape of the input data. Since each thread corresponds to a single pixel, a natural division is using 2 dimensions. We can group threads into 16x16 blocks, meaning each block will process a 16x16 patch of the image. Since we are not using multiple threads per the z-axis, we leave it at 1.
The grid dimension tells us how many blocks per dimension to create. Since we need to cover the whole image using 16x16 patches, we need width/16 blocks in the x direction and height/16 blocks in the y direction. In case our image dimensions don’t divide evenly by 16, we round up.
This rounding means that we might need to spawn some extra blocks where only some threads are utilized. To make sure these unused threads behave correctly, we added the conditional check in our kernel. Only threads that have a corresponding pixel will do some work!
Oof, that’s a lot of low-level details!
So, why 16x16 blocks? In our case, it is pretty arbitrary. We could’ve used 8x8 blocks or 32x32. There’s a hard limit on the number of threads per block, which is usually 1024 on recent cards. As far as I understand, properly organizing threads into blocks and threads can improve performance thanks to memory locality.
Finally, let’s compile and run our code. I’m using BLUR_SIZE=31 for an extra blurry effect.
We can compile this with NVCC to yield the blurred image.


You might wonder if we can run code directly on the GPU without any intervention of the CPU. As far as I know, that’s not possible. Our executable makes calls to cuda runtime API, which in turn communicates with the GPU drivers. However, it’s possible to chain kernels to keep as much of the computation on the GPU without CPU intervention.
If you would like to learn more about this area, consider checking out the book Programming Massively Parallel Processors and the official CUDA C++ Programming guide from Nvidia.
Thanks for reading! If you enjoyed this write-up, you might enjoy my previous one where I explain how MapReduce works by building it from scratch!
Researching and writing these articles takes a lot of time and effort. To ensure you don’t miss the next one, consider subscribing or following me on LinkedIn.
Seems pretty similar conceptually to working with shaders, which is not surprising.
Notably there's some weird stripey artifacts in your output that I would guess are the edge pixels of each block being blurred with the void. But I didn't go over your code in detail.